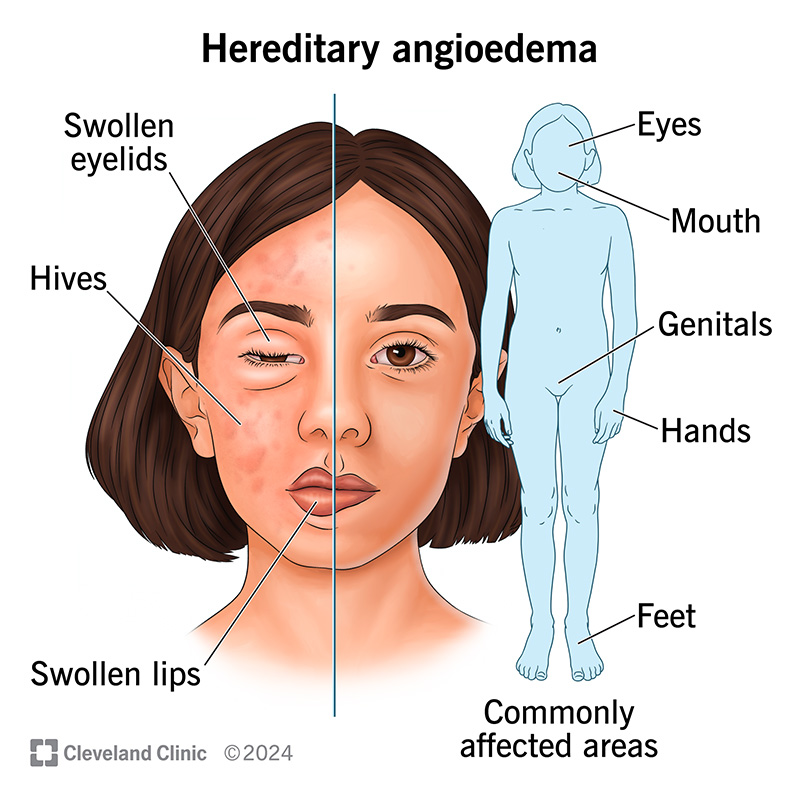
The Curious Case of Missing Medical Information: When "Hereditary Disease" Searches Go Astray
In an age where information is supposedly at our fingertips, the expectation is that a search for critical health topics will yield authoritative and relevant results. When someone types "é ºä¼ å 疾患 ã ¨ ã ¯" (hereditary disease) into a search engine, they are typically seeking definitions, causes, symptoms, treatment options, or perhaps support resources for a condition that affects individuals and families deeply. The intent is clear: to gain understanding about a complex and often sensitive medical subject. However, what happens when the search results deviate dramatically from this expectation? Our recent analysis of sample web contexts revealed a surprising absence of information pertaining to hereditary diseases, instead unearthing content ranging from word game hints to technical domain data. This stark discrepancy begs the question: why was crucial hereditary disease information absent in these specific web contexts, and what does this imply for both users and content creators?
Deconstructing the Irrelevant: What We Found Instead
The sampled web contexts, which were expected to provide insights into "é ºä¼ å 疾患 ã ¨ ã ¯", offered a fascinating, albeit unhelpful, array of unrelated content. This observation highlights a potential disconnect between user search intent and the indexed content available in certain corners of the internet. It underscores the challenges search engines face in interpreting queries and the paramount importance of producing highly relevant, high-quality content, especially for sensitive topics like health.
Word Games and Puzzles: A Curious Detour
One of the unexpected findings was content related to "Today's Connections Hints and Answers," a clear indication of a word game or puzzle solution. For a user earnestly searching for information on "hereditary disease," stumbling upon game hints would be not just unhelpful, but potentially frustrating. How could a search algorithm connect a profound medical term like "é ºä¼ å 疾患 ã ¨ ã ¯" with recreational puzzles? Possible explanations include:
- Broad Keyword Matching: The search algorithm might have performed a very broad match, finding isolated terms within the game hints that were loosely related, or perhaps the site had some very tangential mentions of health terms that were not the core focus.
- Low-Quality SEO or Content Scarcity: In certain niche or less-indexed corners of the web, if authoritative medical content on "hereditary disease" is scarce, search engines might fall back on less relevant but text-rich pages.
- Website Structure and Context: The way a website is structured and the overall context of its content can influence how search engines categorize and present it. A site predominantly about games, even with a stray medical term, will likely be indexed as a game site.
Technical Data and Domain Analysis: A Deep Dive into Code, Not Health
Even more perplexing were the results derived from sources like P-pool.jp and Yaezawa.com. Instead of medical articles, these sites presented an array of technical information, including domain registration details, server specifics, and SEO recommendations. This is akin to searching for a recipe and getting an instruction manual for a microwave oven – while tangentially related to food preparation, it misses the mark entirely. This type of irrelevance is particularly stark because technical data about websites (who owns them, what servers they use, their SEO health) has absolutely no bearing on the meaning, causes, or implications of "é ºä¼ å 疾患 ã ¨ ã ¯".
The presence of such results in a sample context indicates:
- Indexation Anomalies: Search engines might index vast amounts of data, including meta-information about websites themselves, which are not intended for direct user consumption in response to a content-based query.
- Lack of High-Quality, Relevant Content: Again, if a particular sample set or search scope is limited, and relevant medical content is not present within that scope, the algorithm might surface whatever text it deems "closest," even if it's technically oriented.
- Specific Search Context Issues: It's possible the 'sample web context' itself was constrained in a way that excluded typical authoritative medical websites, thereby highlighting a very particular slice of the internet where medical information simply wasn't a priority.
Bridging the Gap: Understanding Search Intent and Algorithm Challenges
The fundamental issue illuminated by the absence of hereditary disease information in these sample contexts is the critical gap between user intent and search engine output. When users search for "é ºä¼ å 疾患 ã ¨ ã ¯", their intent is profoundly serious and health-oriented. They are looking for reliable, empathetic, and medically accurate information. The inability of the sampled contexts to provide this highlights a significant challenge for search algorithms and content creators alike.
User Intent is King: Search engines strive to understand the underlying intent behind a query. For a term like "hereditary disease," the intent is almost always informational and often deeply personal. Users want to know: "What is it?", "How does it affect people?", "What are the latest research findings?", and "Where can I find support?" Any content that fails to address these core questions, such as word game hints or server logs, fundamentally misunderstands this intent.
How Search Algorithms Work (and Sometimes Don't): Modern search algorithms are incredibly sophisticated, employing natural language processing, machine learning, and vast indexes to match queries with the most relevant content. They consider hundreds of ranking factors, including keywords, content quality, backlinks, user engagement signals, and the authority of the website. However, they are not infallible. The observed irrelevant results suggest that in certain specific "sample web contexts," the algorithm either encountered a lack of truly relevant content or struggled to correctly interpret the semantic context of the query against the available text. This can lead to a phenomenon where, in the absence of high-quality, directly matching content, less relevant but keyword-containing pages might surface.
Understanding these challenges is crucial for both users navigating the digital landscape and for anyone creating content for the web. For a deeper dive into why search results sometimes miss the mark for vital health topics, you might find Understanding Irrelevant Search Results for Hereditary Disease particularly insightful.
Crafting Relevant Content: Strategies for Medical Information & SEO
The insights from these sample web contexts underscore the immense responsibility and opportunity for medical content creators and SEO professionals. To ensure that searches for "é ºä¼ å 疾患 ã ¨ ã ¯" genuinely lead to helpful, accurate information, specific strategies must be employed.
For Content Creators: Ensuring E-A-T and Relevance
For YMYL (Your Money Your Life) topics like health, Google places a strong emphasis on E-A-T: Expertise, Authoritativeness, and Trustworthiness. This is non-negotiable for medical content:
- Thorough Keyword Research: Beyond "é ºä¼ å 疾患 ã ¨ ã ¯", research related long-tail keywords, patient questions, and common misconceptions. Include terms like "genetic disorders explained," "inherited conditions symptoms," "causes of hereditary diseases," and specific disease names.
- Expert Authorship: Content must be written by, or rigorously reviewed by, qualified medical professionals (doctors, genetic counselors, researchers). Clearly display author credentials.
- Comprehensive and Accurate Information: Provide clear definitions, detailed explanations of causes (genetic mutations, inheritance patterns), comprehensive lists of symptoms, diagnostic methods, current treatment options, management strategies, and prevention where applicable. Ensure all medical facts are up-to-date and evidence-based.
- Clear Structure and Readability: Use headings, bullet points, and short paragraphs to make complex information digestible. A table of contents can significantly improve user experience.
- Schema Markup: Implement structured data (e.g., MedicalCondition schema) to help search engines understand the specific type of content and its relevance to medical queries. This can improve visibility in rich snippets.
- Internal and External Linking: Link to other relevant pages on your site (e.g., specific hereditary conditions) and to highly authoritative external sources (e.g., National Institutes of Health, World Health Organization, university research centers).
- User Experience (UX): Ensure your website is mobile-friendly, loads quickly, and is easy to navigate. A good UX signals quality to search engines and keeps users engaged.
- Regular Updates: Medical knowledge evolves rapidly. Regularly review and update your content to reflect the latest research and guidelines.
For Users: Navigating Search Results Effectively
While content creators strive for relevance, users can also adopt strategies to find better information:
- Refine Your Queries: Instead of just "é ºä¼ å 疾患 ã ¨ ã ¯", try "what is hereditary disease definition," "symptoms of genetic disorders," or "treatment for inherited conditions." Adding terms like "Mayo Clinic" or "NIH" can also help filter for authoritative sources.
- Prioritize Reputable Sources: Look for results from well-known medical institutions, government health organizations, university hospitals, and established patient advocacy groups.
- Check for E-A-T: Always look for author credentials, publication dates, and references to scientific studies. Be skeptical of anonymous sources or sites making sensational claims.
For more insights into the varied landscape of search results for hereditary diseases, including unexpected ones, consider reading Hereditary Disease Search: Word Games & Technical Data Insights.
Conclusion
The surprising absence of relevant information about "é ºä¼ å 疾患 ã ¨ ã ¯" in the sampled web contexts serves as a powerful reminder of the complexities of information retrieval in the digital age. While it's reassuring that these specific samples do not reflect the entirety of the internet's medical knowledge, they highlight potential vulnerabilities in how content is indexed and presented. For individuals seeking crucial health information, encountering word game hints or technical domain data can be confusing and unproductive. This situation underscores the critical need for content creators to adhere to the highest standards of accuracy, authority, and relevance, especially for sensitive topics like hereditary diseases. By focusing on E-A-T, comprehensive coverage, and user-centric design, we can collectively ensure that when users search for vital medical terms, they are met with the informed and trustworthy resources they so desperately need.